Основные структуры данных: Ассоциативный массив
Ассоциативный массив (Map) — это структура, которая хранит данные в парах ключ/значение, где каждый ключ уникален. Иногда её также называют ассоциативным массивом или словарём. Map часто используют для быстрого поиска данных. Она позволяет делать следующие вещи:
- добавлять пары в коллекцию;
- удалять пары из коллекции;
- изменять существующей пары;
- искать значение, связанное с определенным ключом.
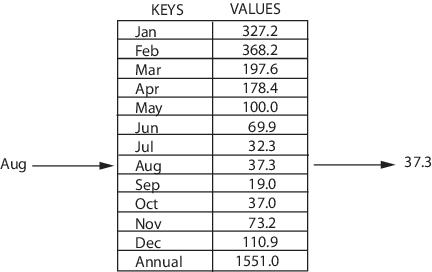
Предполагается, что ассоциативный массив не может хранить две пары с одинаковыми ключами.
В паре  значение
значение  называется значением, ассоциированным с ключом
называется значением, ассоциированным с ключом  . Семантика и названия вышеупомянутых операций в разных реализациях ассоциативного массива могут отличаться.
. Семантика и названия вышеупомянутых операций в разных реализациях ассоциативного массива могут отличаться.
значение называется значением, ассоциированным с ключом . Семантика и названия вышеупомянутых операций в разных реализациях ассоциативного массива могут отличаться.
Операция FIND(ключ) возвращает значение, ассоциированное с заданным ключом, или некоторый специальный объект UNDEF, означающий, что значения, ассоциированного с заданным ключом, нет. Две другие операции ничего не возвращают (за исключением, возможно, информации о том, успешно ли была выполнена данная операция).
Ассоциативный массив с точки зрения интерфейса удобно рассматривать как обычный массив, в котором в качестве индексов можно использовать не только целые числа, но и значения других типов — например, строки.
Реализация
Существует множество различных реализаций ассоциативного массива.
Самая простая реализация может быть основана на обычном массиве, элементами которого являются пары (ключ, значение). Для ускорения операции поиска можно упорядочить элементы этого массива по ключу и осуществлять нахождение методом бинарного поиска. Но это увеличит время выполнения операции добавления новой пары, так как необходимо будет «раздвигать» элементы массива, чтобы в образовавшуюся пустую ячейку поместить новую запись.
Наиболее популярны реализации, основанные на различных деревьях поиска. Так, например, в стандартной библиотеке STL языка С++ контейнер map реализован на основе красно-чёрного дерева. В языках Ruby, Tcl, Python используется один из вариантов хэш-таблицы. Есть и другие реализации.
У каждой реализации есть свои достоинства и недостатки. Важно, чтобы все три операции выполнялись как в среднем, так и в худшем случае за время  , где
, где  — текущее количество хранимых пар. Для сбалансированных деревьев поиска (в том числе для красно-чёрных деревьев) это условие выполнено.
— текущее количество хранимых пар. Для сбалансированных деревьев поиска (в том числе для красно-чёрных деревьев) это условие выполнено.
, где — текущее количество хранимых пар. Для сбалансированных деревьев поиска (в том числе для красно-чёрных деревьев) это условие выполнено.
В реализациях, основанных на хэш-таблицах, среднее время оценивается как  , что лучше, чем в реализациях, основанных на деревьях поиска. Но при этом не гарантируется высокая скорость выполнения отдельной операции: время операции INSERT в худшем случае оценивается как
, что лучше, чем в реализациях, основанных на деревьях поиска. Но при этом не гарантируется высокая скорость выполнения отдельной операции: время операции INSERT в худшем случае оценивается как  . Операция INSERT выполняется долго, когда коэффициент заполнения становится высоким и необходимо перестроить индекс хэш-таблицы.
. Операция INSERT выполняется долго, когда коэффициент заполнения становится высоким и необходимо перестроить индекс хэш-таблицы.
, что лучше, чем в реализациях, основанных на деревьях поиска. Но при этом не гарантируется высокая скорость выполнения отдельной операции: время операции INSERT в худшем случае оценивается как . Операция INSERT выполняется долго, когда коэффициент заполнения становится высоким и необходимо перестроить индекс хэш-таблицы.
Хэш-таблицы плохи также тем, что на их основе нельзя реализовать быстро работающие дополнительные операции MIN, MAX и алгоритм обхода всех хранимых пар в порядке возрастания или убывания ключей.
Реализация интерфейса телефонной книги на языке C++:


